
外刊阅读 | 麻省理工技术评论 | DeepSeek 如何打破 AI 规则?
在AI技术日新月异的今天,DeepSeek,中国初创公司正以惊人的速度崛起,它不仅打破了传统的AI规则,还引领了一场全球范围内的效仿浪潮。那么,DeepSeek究竟是如何做到这一点的?它的创新之处又为何让每个人都跃跃欲试呢?DeepSeek,这家成立于2023年的创新型科技公司,专注于开发先进的大语言模型(LLM)和相关技术。其最新发布的R1模型,在数学、代码、自然语言推理等任务上,性能比肩美国开放人工智能研究中心(OpenAI)的o1模型,但训练成本却远低于后者。这一突破性成就不仅震惊了硅谷,还引发了全球AI领域的广泛关注。
How DeepSeek ripped up the AI playbook DeepSeek 如何打破 AI 规则 1 When the Chinese firm DeepSeek dropped a large language model called R1 last week, it sent shock waves through the US tech industry. Not only did R1 match the best of the homegrown competition, it was built for a fraction of the cost—and given away for free.The US stock market lost $1 trillion, President Trump called it a wake-up call, and the hype was dialed up yet again. “DeepSeek R1 is one of the most amazing and impressive breakthroughs I’ve ever seen—and as open source, a profound gift to the world,” Silicon Valley’s kingpin investor Marc Andreessen posted on X. homegrown /ˌhoʊmˈɡroʊn/ adj. 国产的 hype /haɪp/ n.吹捧,炒作 kingpin /ˈkɪŋpɪn/ n.主要人物 By publishing details about how R1 and a previous model called V3 were built and releasing the models for free, DeepSeek has pulled back the curtain to reveal that reasoning models are a lot easier to build than people thought. The company has closed the lead on the world’s very top labs.The news kicked competitors everywhere into gear. This week, the Chinese tech giant Alibaba announced a new version of its large language model Qwen and the Allen Institute for AI (AI2), a top US nonprofit lab, announced an update to its large language model Tulu.DeepSeek has suddenly become the company to beat. What exactly did it do to rattle the tech world so fully? Is the hype justified? And what can we learn from the buzz about what’s coming next? curtain n.帷幔;窗帘 kick sth into gear 开始工作 rattle /ˈræt(ə)l/ v.使紧张 rattle sb's cage 骚扰;使恼怒 Let’s start by unpacking how large language models are trained. There are two main stages, known as pretraining and post-training. Pretraining is the stage most people talk about. In this process, billions of documents—huge numbers of websites, books, code repositories, and more—are fed into a neural network over and over again until it learns to generate text that looks like its source material, one word at a time. What you end up with is known as a base model.Pretraining is where most of the work happens, and it can cost huge amounts of money. Turning a large language model into a useful tool takes a number of extra steps. This is the post-training stage, where the model learns to do specific tasks like answer questions (or answer questions step by step, as with OpenAI’s o3 and DeepSeek’s R1). The way this has been done for the last few years is to take a base model and train it to mimic examples of question-answer pairs provided by armies of human testers. This step is known as supervised fine-tuning. unpack /ˌʌnˈpæk/ v.分析;卸下…… stage /steɪdʒ/ n. 阶段,时期 mimic /ˈmɪmɪk/ v. 模仿 fine-tuning n. 微调;细调 OpenAI then pioneered yet another step, in which sample answers from the model are scored—again by human testers—and those scores used to train the model to produce future answers more like those that score well and less like those that don’t. This technique, known as reinforcement learning with human feedback (RLHF), is what makes chatbots like ChatGPT so slick. RLHF is now used across the industry.But those post-training steps take time. What DeepSeek has shown is that you can get the same results without using people at all—at least most of the time. DeepSeek replaces supervised fine-tuning and RLHF with a reinforcement-learning step that is fully automated. Instead of using human feedback to steer its models, the firm uses feedback scores produced by a computer. pioneer /ˌpaɪəˈnɪr/ v.倡导;开辟 reinforcement learning 强化学习 slick /slɪk/ adj. 熟练的 steer /stɪr/ v.驾驭,训练 The downside of this approach is that computers are good at scoring answers to questions about math and code but not very good at scoring answers to open-ended or more subjective questions. That’s why R1 performs especially well on math and code tests. To train its models to answer a wider range of non-math questions or perform creative tasks, DeepSeek still has to ask people to provide the feedback.To build R1, DeepSeek took V3 and ran its reinforcement-learning loop over and over again. downside /ˈdaʊnsaɪd/ n. 缺点 subjective /səbˈdʒektɪv/ adj.主观的 To start with, the model did not produce answers that worked through a question step by step, as DeepSeek wanted. But by scoring the model’s sample answers automatically, the training process nudged it bit by bit toward the desired behavior.Eventually, DeepSeek produced a model that performed well on a number of benchmarks. But this model, called R1-Zero, gave answers that were hard to read and were written in a mix of multiple languages. To give it one last tweak, DeepSeek seeded the reinforcement-learning process with a small data set of example responses provided by people. Training R1-Zero on those produced the model that DeepSeek named R1.But why now? There are hundreds of startups around the world trying to build the next big thing. Why have we seen a string of reasoning models like OpenAI’s o1 and o3, Google DeepMind’s Gemini 2.0 Flash Thinking, and now R1 appear within weeks of each other?The answer is that the base models—GPT-4o, Gemini 2.0, V3—are all now good enough to have reasoning-like behavior coaxed out of them.What R1 shows is that with a strong enough base model, reinforcement learning is sufficient to elicit reasoning from a language model without any human supervision. nudge /nʌdʒ/ v.达到,接近 tweak n.稍稍调整 elicit /ɪˈlɪsɪt/ v. 引出,得到 supervision /ˌsuːpərˈvɪʒ(ə)n/ n. 监督 Journal:technologyreview Title:How DeepSeek ripped up the AI playbook—and why everyone’s going to follow its lead(January 31, 2025) Category:Artificial intelligence END 写作句式积累 The news kicked competitors everywhere into gear. 这一消息让世界各地的竞争对手纷纷采取行动。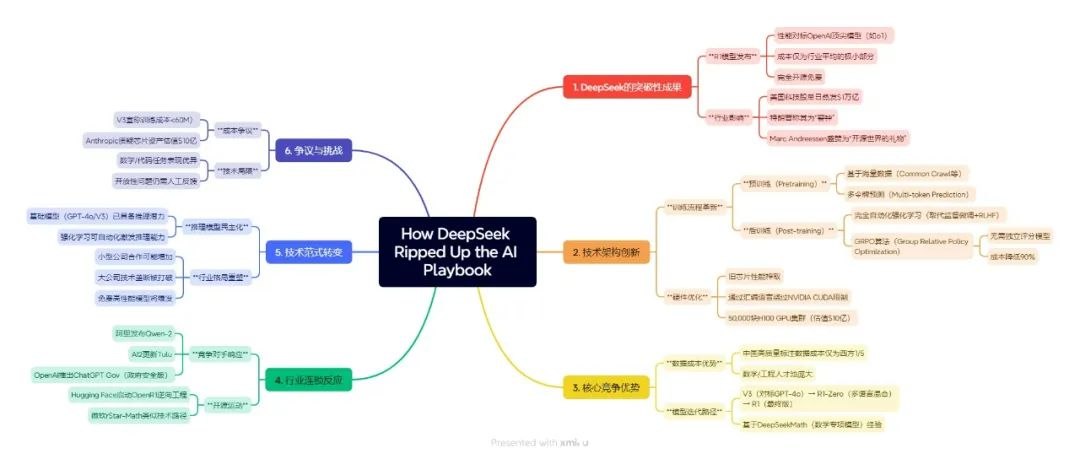



相关文章
- 外刊选读 Appa’s Crossword Magic
- 外刊选读The Week Junior|Should people get time off to care for pets?
- 英文名著|原版英语阅读导读|哈利波特与魔法石第6章 导读手册+音频
- 外刊阅读 | 麻省理工技术评论 | DeepSeek 如何打破 AI 规则?
- 外刊精读 | 春节申遗成功 China’s Spring Festival inscribed as UNESCO ICHH
- 外刊精读 | 新能源汽车的优点和缺点
- 外刊精读 | 如何让自己的新年计划不流于形式
- 经常午睡比不午睡更健康吗?Whether naps have short- and long-term benefits for your health
发表评论